Data is hard to manage and databases are hard to test. Database deployments are far more complicated than application deployment, since you cannot redeploy your code from scratch every time. Database automation is tough and more often it’s the fear of messing up the critical data that can pause the forward development and slow down business delivery.
In this article, you will learn about an open source tool called Flyway and how it makes database migrations easier.
![]()
What is Continuous Integration?
Continuous Integration is a development practice which encourages developers to check in code changes to source control as frequently as possible. Since the code is checked in and integrated more often in smaller pieces, it is easier to identify and resolve issues at an earlier stage. Every code commit triggers an automated build in a separate CI server and executes the unit and integration tests. Code Quality is maintained since any build which has failing tests are not allowed to get checked in to source control repository.
One important thing which you need to remember is that you cannot do Continuous Integration without Source control.
In short, to achieve Continuous Integration you need to be performing the below 5 activities —
- Maintaining Source Control
- Smaller Code Commits
- Frequent Code Check ins
- Automated Builds
- Automated Testing
Why is Flyway needed?
While implementing the data layer for your application, you will need to think about the migration strategy for your DDL and DML scripts. Handling changes in your relational database might be additional complicacy, since you need to find the current state of the database and track which scripts have executed against different environments.
All database scripts need to be checked in to Source Control, which should be the single source of truth.
The top 5 reasons for using Flyway are —
- Flyway is free and open source.
- Flyway is lightweight and easy to setup.
- Flyway facilitates the Automatic Deployment of database changes.
- Flyway makes the current state of the database explicit and clear.
- Flyway lets you recreate your database from scratch – it keep track of the DDL/DML scripts that have executed against a particular database environment.
How to enable Flyway in your project?
Include flyway dependency under dependencies in build.gradle file —
compile group: ‘org.flywaydb’, name: ‘flyway-core’, version: “${project.ext[‘flywayVersion’]}”
Include flyway settings in application.yml file –
flyway:
enabled: true
schemas: <db_schema_name>
locations: classpath:/sql
The way this tool work is that it scans an appropriate folder with SQL scripts and executes them against your database during the project startup.
How does Flyway work?
If you want to spin up a new DB instance in another environment, Flyway can do it for you in a breeze. At application startup, it tries to establish a connection to the database. It will throw an error, if it is not able to.
It helps you evolve your database schema easily and is reliable in all instances. There is no need to execute the database scripts manually.
Every time the need to upgrade the database arises, whether it is the schema (DDL) or reference data (DML), you can simply create a new migration script with a version number higher than the current one. When Flyway starts, it will find the new script and upgrade the database accordingly.
Flyway scans the file system and sorts them based on their version number.
Flyway creates a table name ‘schema_version‘ in your database. This table is responsible for tracking the state of the database and keeps an explicit record for the various sql scripts that has been executed. As each migration gets applied, the schema history table is updated.
![]()
Things to keep in mind while working with Flyway —
Do not modify the SQL file which has been already deployed. If you want to deploy even the slight variation of an already existing script, make sure to create a new sql file.
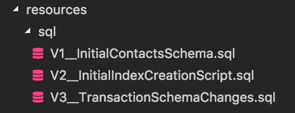
Naming convention of the SQL Files —
V<version_sequence>__description_of_the_script.sql
Keep a note of the double underscore – the separator between the sequence and the description.
What are the databases that Flyway supports?
Supported databases are Oracle, SQL Server (including Amazon RDS and Azure SQL Database, DB2, MySQL (including Amazon RDS, Azure Database & Google Cloud SQL), MariaDB, PostgreSQL (including Amazon RDS, Azure Database, Google Cloud SQL & Heroku), Redshift, CockroachDB, SAP HANA, Sybase ASE, H2, HSQLDB, Derby and SQLite.
For more details around Flyway, please refer —
Are you using Flyway in your organization? Are you implementing Flyway for your Database Migrations and facing issues? If Yes, please put a comment below and I will be happy to assist.
Categories: DevOps, Flyway, SQL Server
 Flyway Error: Found non-empty schema(s) without schema history table
Flyway Error: Found non-empty schema(s) without schema history table 
We are considering to improve our DB (MS SQL/Azure SQL based) development workflow, and looking for some good tool for it. Our man challenge is that in addition to “ordinal” change scripts we also have quite a lot of stored procedures (mainly because of legacy enterprise reasons).
We kind of forced to treat stored procedures as code, because there are parts of business logic (legacy reasons again). So for us it’s not a good idea to have same stored procedure distributed among different change scripts. We would like to keep stored procedures code basically as any other code files, or something like that.
This post came out at a right time, although I didn’t hear about Flyway previously, so I’m curious a bit – e.g. how is it different comparing to Visual Studio DB project, Redgate DB solutions, or such libraries like DbUp (https://github.com/DbUp/DbUp)?
Do you have any quick answer if Flyway could provide some flexible workflow to what I wrote above about stored procedures?
Does it provide any smart support for feature branches (e.g. when change scripts are created in different branches)? You wrote about DB source control and CI – and CI nowadays hardly imagined without feature branches.;)
LikeLiked by 1 person
Since you are working on SQL Server, I would highly recommend you to use Database Project for your usecase. There are lot of additional functionalities which SQL Server Data Tools provides out of the box. For data intensive large sized dev projects, I personally prefer the State based approach(SSDT), where I do not have to write ALTER scripts. The DACPAC deployments makes lives lot easier.
Flyway is a Java based tool and is a preferred option with Java projects.
Flyway supports a wide variety of databases(including SQL Server) and since I am currently building a microservice using Java, Netflix OSS and AWS Aurora – I went with Flyway.
Thanks for your comment. I will modify my article to add this point as well.
LikeLiked by 1 person
As I work for Redgate I’m able to confirm that ReadyRoll will auto-generate the ALTER scripts for you, so there’s no requirement to write them. The advantage of this approach is that, unlike with the state-based approach, if you _do_ happen to need to customise your migration scripts, you are able to do so. ReadyRoll Core is licensed with Visual Studio Enterprise. If you don’t own a license for this, it’s available as part of the Redgate SQL Toolbelt. I hope this helps!
LikeLiked by 1 person
Thanks David and I agree with your comment.
ReadyRoll has its own advantages and would be nice to use if you want to have more fine grained control on your database scripts. I have bumped into scenarios with State Based approach where I need multiple steps to complete the refactoring, which ReadyRoll could have handle it like a champ in a single step.
However being a developer and working on a Greenfield project, I have realized that with Migration based approach, you will eventually end of with a long list of migration scripts within your source control which you need to maintain. Also there is no way to see the current state of your database objects inside your source control, you need to look at the database since that’s the source of truth.
I have couple of questions for you —
Does ReadyRoll provide an option to block the deployment if Data loss occurs?
Does ReadyRoll provide some baselining approach where you can compress/reduce the number of deployment scripts to a single file once you reach a number of files(say 100) or a period of time(say 1 year)? That way at the end of the development phase of a Greenfield project I can automatically baseline the current version into source control and go from there.
LikeLike
Yes, the long list of migration scripts is a common concern. ReadyRoll has a feature that mitigates this called. If you enable “Programmable Objects”, it treats stored procedures, functions, triggers and views differently to tables. Instead of creating a new migration script for these changes, it will managed them separately as DROP/CREATE scripts, run at the end of the migrations process.
Also, ReadyRoll maintains an “offline schema model”, which is effectively the “state” that gives you the object level history. Unlike with SSDT and SQL Source Control, this is used for object versioning only, and not for deployment.
To answer your questions.
1) ReadyRoll doesn’t block deployment if data loss occurs. Instead it shows you the script for every change so you can validate at development time that the change is as you expect.
2) Yes, there is a baselining feature in ReadyRoll. However, the Programmable Objects feature I described above will also go a long way to mitigate any concerns about the number of scripts that a traditional migrations approach suffers from.
It’s worth saying that the offline schema model and the programmable objects features are not in ReadyRoll Core, but in the full SQL Toolbelt version only.
LikeLiked by 1 person
Thanks for the details David. These are the exact concerns I had and I am glad it is a solved problem.
The Programmable Objects and the Offline Schema Model are nice features and brings in the best from the State Based world. It makes me sad that it is not part of ReadyRoll Core. I am sure the adaption of ReadyRoll would be lot higher among the .NET Developers if these 2 features were available with VS 2017.
LikeLike
Hi.
We are using Aurora PostgreSQL as our Database and we want to have a CI\CD pipeline in place for just database part so is it possible to do CI\CD process setup for Aurora PostgreSQL if we can do that then can you please tell me what are the steps we need to follow using the flyway. If you pass on some useful web urls that would be greatly appreciated..
LikeLike
hi @Srinivas
I am even looking for the same. we have Aurora PostgreSQL in AWS RDS. Looking to implement CI/CD
Please tell me if you have any solution for this. Thanks in advance.
LikeLike
We are moving from on-prem EDB Postgres 9.3 to AWS RDS Postgres – I am new to AWS and have not used flyway as well. Is it possible for you to post steps on how to setup flyway and use it for CI on AWS.
LikeLike